
卷积网络往往被应用于计算机视觉领域。CNN处理的图像或者视频中的像素点是排列成很整齐的矩阵,也就是欧几里得结构。但在现实生活中还有非常多的非欧几里得结构,例如化学分子结构,例如社交网络结构。但CNN在处理非欧几里得结构时的能力是有限的,因为在非欧几里得结构的数据上无法保持平移不变性,不能使用固定尺寸的卷积核进行卷积运算。而GCN则主要是针对这一问题而生的,它可以用来在非欧几里得结构的拓扑图上有效地提取到空间信息来进行机器学习。GCN主要借助于图的拉普拉斯矩阵的特征值和特征向量来研究图的性质。
将GCN与推荐系统相结合的灵感来源于Kipf的论文Graph Convolutional Matrix Completion,在这片论文中,在已知用户对一部分已购商品的评分时,可以通过GCN来预测对于其他未购买的商品的评分。
在这一篇周记中,我主要是将一些想法应用到了Cora数据集上。Cora数据集是由机器学习论文组成的,是近年来图深度学习很喜欢使用的数据集。在数据集中,每一篇论文引用或被至少一篇其它论文引用。通过Cora数据集我们可以构建一张引用网络,即,每篇论文是一个结点,存在引用和被引用关系的论文之间存在边。
在训练了GCN模型之后,我对梯度进行了一步反向传播。在下图的例子中,结点119应该被预测为类别5, 但是被错误地预测为类别3。通过对梯度的反向传播,可以得到对于该结点做出正确预测影响力最大的点。在这一例子中,影响力最大的点是结点1与结点119之间的边。

我们将这条边加入模型中,可以看到模型给出了正确的预测。同时这也证明了,梯度更大的点确实具备更大的影响力。

以上的例子是模型给出错误预测时,通过添加影响力大的边,我们可以引导模型做出正确的预测。而下例则是在模型给出正确预测时,添加影响力大的边,我们也可以干扰模型使模型做出不正确的预测。

对于结点140, 正确的预测结果应是类别三,而模型给出了正确的预测结果。当我们添加此时影响力最大的边,即边(140,1), 我们可以使模型给出不正确的类别。

接下来我可视化了在添加边或删除边的过程中,仅局部会产生较大的影响,而不会对全局产生很大的影响。图中圆点表示结点,圆点上的数字表示论文索引,边的深浅表示标准化的梯度大小。
这一实验证明了添加或删除梯度大,也就是影响力更大的边可以引导模型做出正确或错误的预测结果。同时,也证明了,添加边或删减边,仅对于相邻的局部的结构有影响,而不会对全局产生较大的影响。
这一数据集的规模较小,且其中只含有一种结点,即论文结点。在接下来的实验中,我又尝试了在二分图上的实验。对于邻接矩阵的表达也做出了相应的修改。
周记二主要是证明了想法的可行性,而在这篇周记中,侧重点主要是将图卷积网络和推荐系统结合起来。同时将单一种类结点的数据集更换为有两类结点的数据集。我使用了MovieLens这一数据集。这一数据集中有两种结点,用户结点和电影结点。用户对看过的电影进行评分,从1分到5分共五档,即边的类别共有五种。数据集中仅一部分边是可观察到的。我的任务是对可观察到的、未观察到的边进行评分预测,并向用户推荐电影。但现实中往往存在有不能推荐成功的情况。例如,我想要想一位用户推荐apple pencil,而该用户从未购买过iPad,因此除非在用户购买过iPad之后再推荐apple pencil,否则推荐是无用的,是失败的。而在这一数据集中,如果我想要向用户推荐电影《星球大战(二)》,并期待用户可以给该电影打高分,首先要想该用户推荐电影《星球大战(一)》。我把这样的推荐定义为Chain Recommendation。
在下面的例子中,我们想要使用户对一部电影的评分更高,我们会向该用户推荐另一部电影。
粉色结点表示用户结点,蓝色结点表示电影结点,绿色结点表示我们期待用户可以给出更高分的电影,紫色结点是我们向用户推荐的另一部电影。
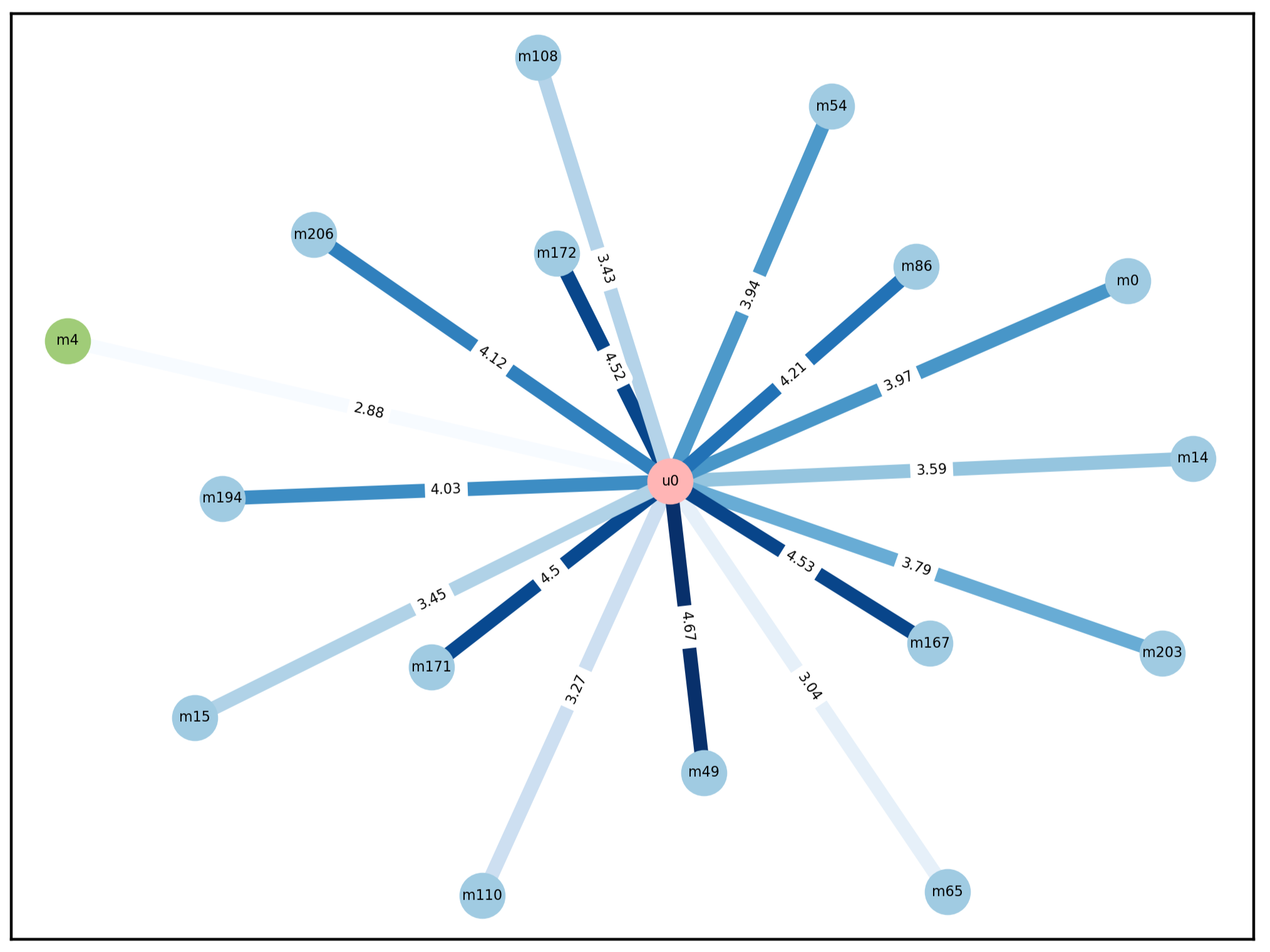
在添加边之前,用户0给电影4的评分为2.88。

在添加边(u0, m321)之后,用户0给电影4从2.88上升到了3.04。
我也尝试了给相似用户推荐电影对原用户给电影评分的影响。
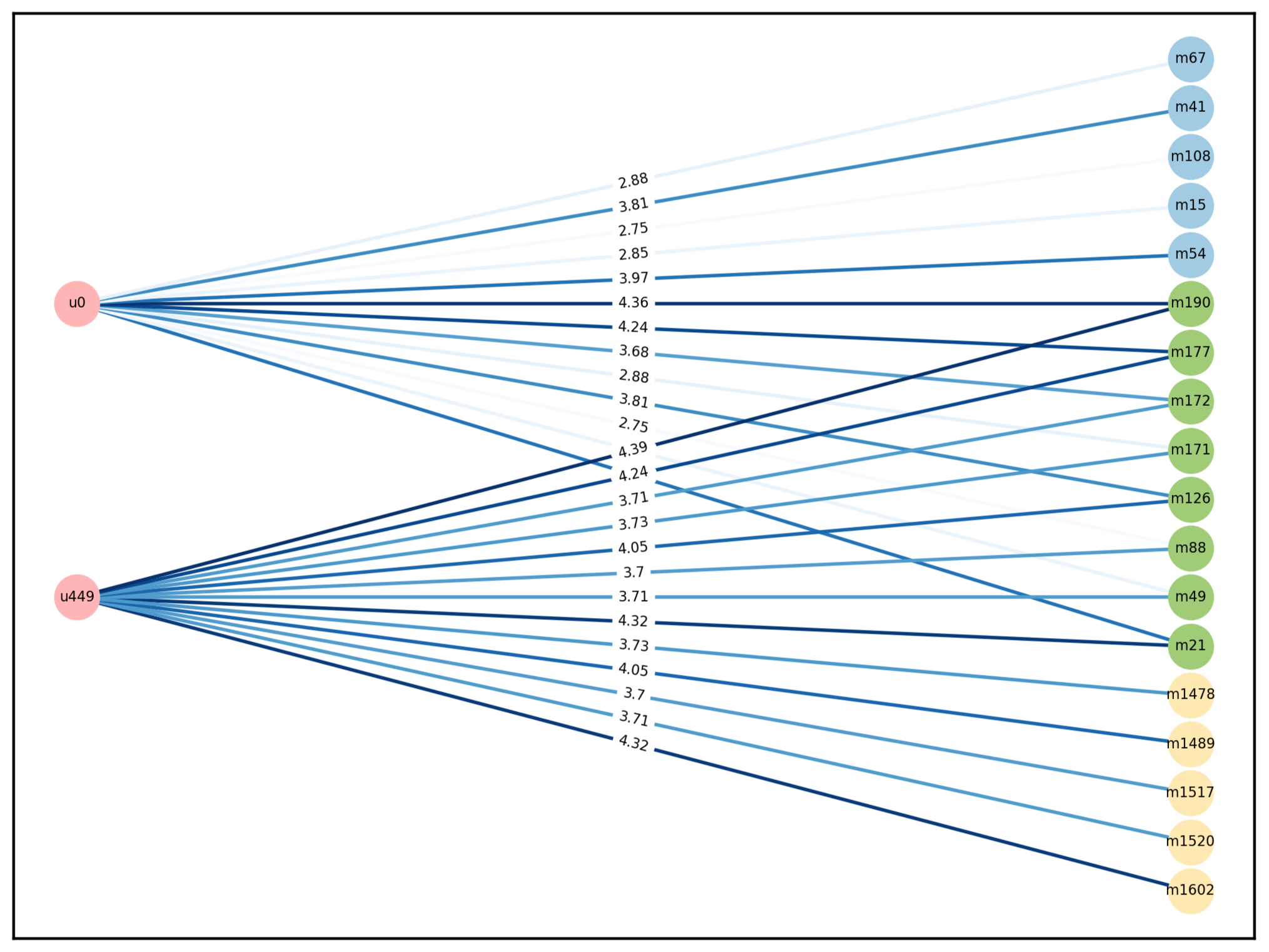
起初用户0对电影67的评分为2.88。

在添加了边(u449,m4)这条边之后,用户0对电影67的评分从2.88上升到了2.9。但该提升并不如给同一位用户直接推荐电影显著。
在证明了课题的可行性,以及证明了在规模更大且具有现实意义的数据集上模型的良好效果后,我细化了课题的走向,并留下了具有现实意义的两条方向备选。
这个课题还有一个非常关键的问题在于如何评估实验的结果。因为根据现有的数据集,我们很难评估我们的推荐在现实中到底又怎样的效果。因此我们将数据集划分为control group和treatment group, 并观察比较模型在treatment group和control group的表现。
接下来我将详细介绍不同的方向以及对应的实验结果。
4.1 设定1
在现实生活中,由于预算往往是有限的,选择如何投放广告从而获得最大收益往往是商家所要考虑的问题。在设定1中,给定一个想要推荐的产品,从全局范围选择K条边。
4.1.1设定1.1
设定:我将数据集主要划分为训练集,选择集与测试集。此处需要选择集的原因是: 对于每部电影而言,共有五个分数,而我们所添加的边的分数应当是符合现实而不是错误地虚高的。该选择集中保留了一部分对训练过程不可见的边,作为添加边时的参考标准。
结果:在control group 和treatment group上的增长于0.01。
一个可能的原因是选择集的规模过小且过于稀疏,因此选择集有用的边是非常有限的。无论是微调(多训练几轮)模型还是直接进行梯度反向传播,结果都是类似的。
结论:由于选择集的缺陷,这一设定是不合理的。
4.1.2 设定1.2
设定: 此处划分数据集的方式与设定1.1中有所不同。我们从所有未观察到的边中筛选边,并设置添加的边的评分为预测值,并且在所有未观察到的边上进行评估。
结果:拥有大梯度的边都与同一个用户相连。
结论:而在现实中,商家或平台不会将所有物品都推销给同一个用户,因此这一设定也是不合理的。
4.2设定2
在设定2中,首先固定一位用户,然后选择商品。例如,当目标商品为i时,对于每一个用户u,我们从所有的未被观察到的边中选择一条边,也就是选择一个商品j。
4.2.1 设定2.1
当我们选择好商品j后,同时添加所有的边。
结果:评分的平均增长是0.018。
4.2.2 设定2.2
在从所有未观测到的边中选择了一个商品j之后,一次只添加一条边。
结果:评分的平均增长为0.220,相对于设定2.1中的0.018有非常大的提升。在这个设定下,我们比较了在随机选边,shortsighted选边以及梯度选边设定下评分的平均增长,以下是实验结果:
Method Average Increase
Random 0.0077
Shortsighted -0.0466
Gradient 0.2200
我们也在control group和treatment group上评估了实验的结果。对于treatment group中的用户u,我们选择一个用户u’,u和u’拥有共同被推荐的商品i,且这两位用户拥有相似的embedding。我们添加边(u,i),与此同时不添加边(u’,i),观察对于control group和treatment group有什么不同的效果。实验结果如下:
Treatment group的平均增长 Control group的平均增长
0.1312 0.0000